
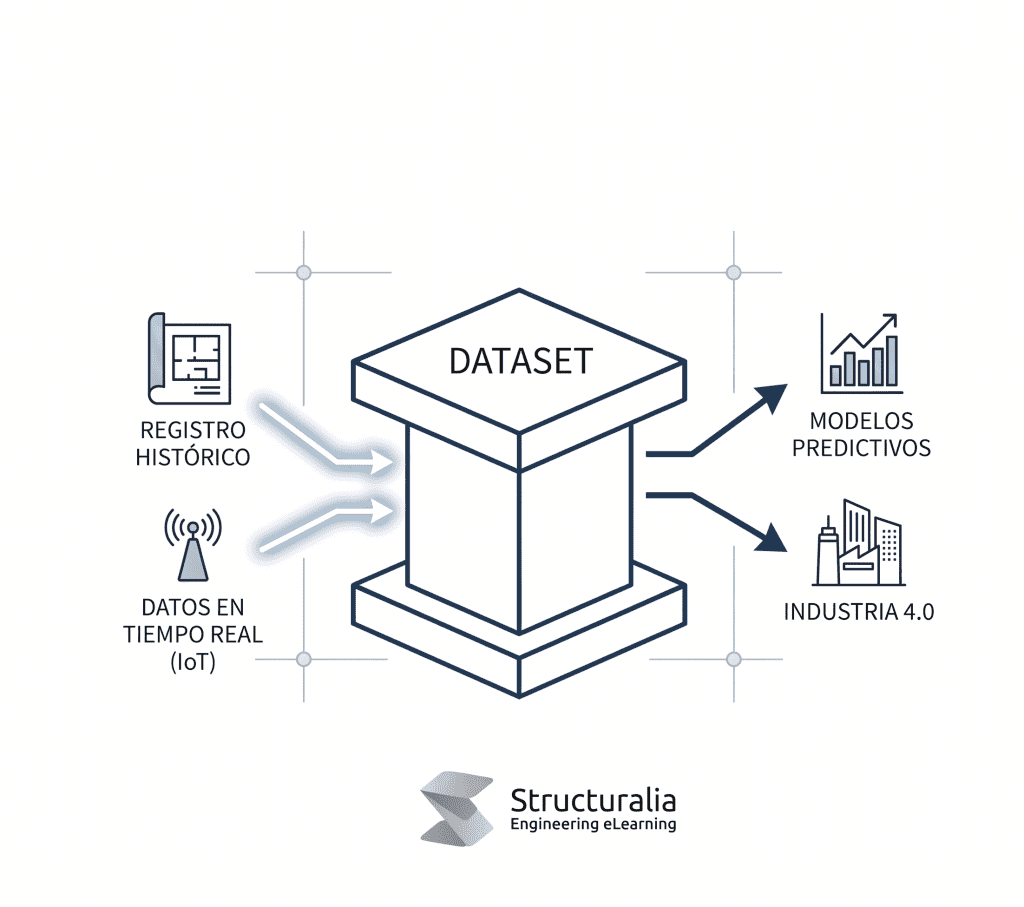
Un dataset es una unidad lógica de información persistente y estructurada que sirve como base para el análisis, la experimentación y el entrenamiento de modelos algorítmicos. El conjunto de datos constituye el registro histórico y en tiempo real de las variables críticas que permiten la transición efectiva hacia la digitalización de infraestructuras. Esta pieza de información es el resultado de un proceso técnico de curaduría que da propósito a cada bit almacenado.
¿Qué son los datasets?
Los datasets son colecciones organizadas de información curada que permiten a los científicos de datos ejecutar análisis de alto impacto. A diferencia del big data en bruto, que suele ser una masa caótica de registros, un dataset implica una intención analítica previa y un esquema definido. Es la infraestructura mínima viable que permite convertir hechos aislados en conocimiento aplicable para la toma de decisiones estratégica en proyectos de alta complejidad técnica.
- Optimización Financiera: se consolida como el activo clave para optimizar presupuestos y reducir riesgos operativos en toda la región.
- Interoperabilidad Global: garantiza la compatibilidad técnica bajo estándares internacionales, permitiendo que una oficina técnica en Madrid y una constructora en México compartan parámetros de resistencia sin desajustes.
- Seguridad Estructural: sostiene la predicción de fallos mediante la normalización de datos críticos.
Diferencia entre dataset y dataframe
El dataset es el activo físico almacenado de forma persistente en servidores o en la nube, generalmente bajo formatos optimizados para big data. Es la fuente original, inmutable y segura, que garantiza la integridad de los registros técnicos históricos frente a cualquier proceso de transformación o error humano durante la fase de análisis activo.
- Abstracción Lógica: el dataframe es la representación del dataset cargada activamente en la memoria RAM para su procesamiento.
- Cálculo Dinámico: permite a los ingenieros realizar operaciones matriciales y filtrados en tiempo real mientras el origen permanece en reposo.
- Naturaleza Efímera: a diferencia del almacenamiento persistente, el dataframe se destruye al finalizar la sesión para proteger la integridad de la base de datos original.
Tipos de Datasets
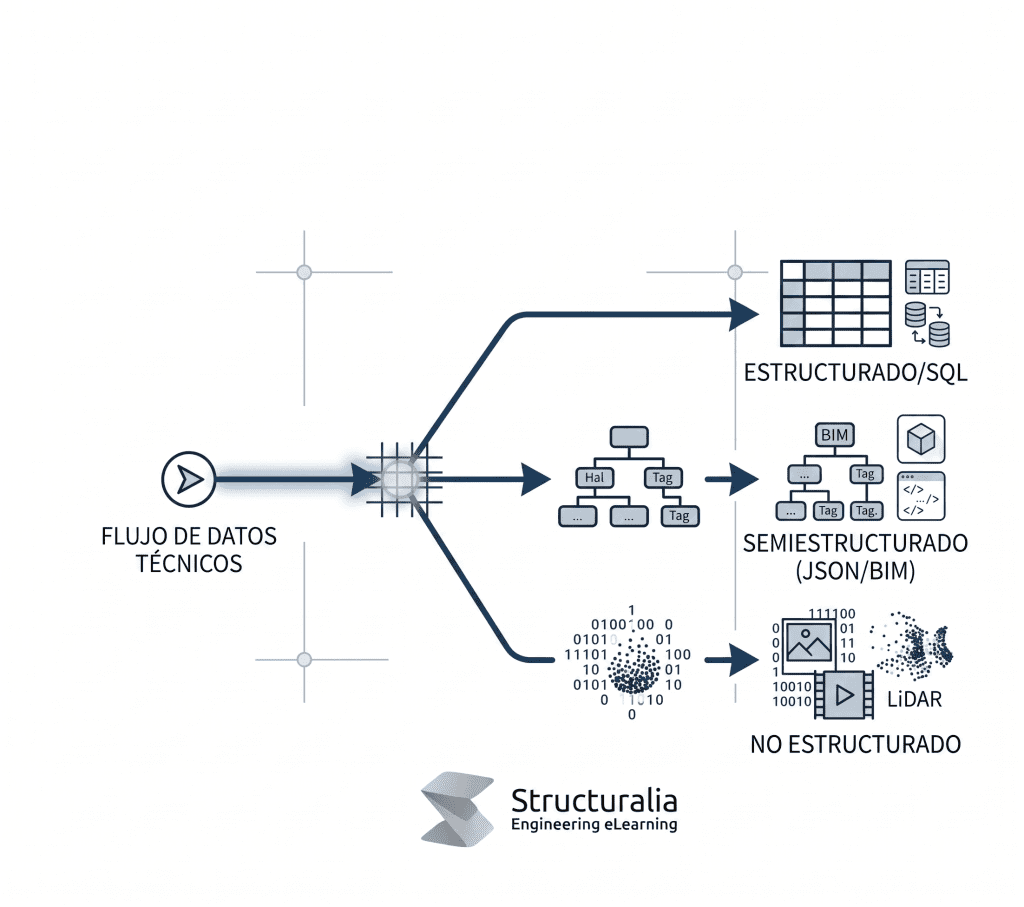
La clasificación de los datasets determina las herramientas de análisis de datos necesarias y el coste de procesamiento asociado. En ingeniería, el tipo de dataset guía a los especialistas hacia la arquitectura de almacenamiento óptima, ya sea mediante sistemas SQL tradicionales o Data Lakes modernos. Esta taxonomía permite organizar la información de modo que se maximice su utilidad operativa y se facilite la integración de nuevas variables durante el ciclo de vida del proyecto.
Datasets estructurados
Los datasets estructurados son la base de la gestión técnica organizada, se caracterizan por un modelo relacional rígido o Schema-on-write. En este tipo de dataset, cada registro encaja en una forma de tablas con columnas y filas predefinidas, lo que garantiza coherencia total. Es el formato estándar en sistemas ERP y bases de datos SQL utilizadas para el control de costes, inventarios de obra y registros de ensayos de laboratorio donde la precisión numérica es innegociable.
Su mayor ventaja operativa es la velocidad de consulta y la facilidad para ejecutar operaciones matemáticas masivas de forma casi instantánea. Al trabajar con tipos de datos fijos los algoritmos de análisis de datos pueden identificar tendencias de rendimiento histórico sin fricciones técnicas. En proyectos de ingeniería regionales, esta estructura es vital para que la toma de decisiones financiera se apoye en métricas sólidas y comparables.
Datasets no estructurados
Los datasets no estructurados representan el mayor volumen de información generada en la ingeniería moderna, aunque su aprovechamiento técnico sea más complejo. Se trata de archivos binarios sin esquema definido, como nubes de puntos LiDAR (Light Detection and Ranging), vídeos de inspección o audios de campo. Para que este conjunto de datos sea útil, requiere capas de inteligencia artificial que traduzcan los píxeles o señales en variables métricas estructuradas que un ingeniero pueda interpretar.
Integrar esta información en estrategias de big data permite monitorizar el avance real de una obra frente al cronograma teórico con una fidelidad imposible de lograr mediante informes manuales. La explotación técnica de lo no estructurado es lo que permite detectar desviaciones críticas en tiempo real, aumentando la capacidad de respuesta y reduciendo drásticamente los sobrecostes por errores de ejecución imprevistos.
Dataset semiestructurado
El dataset semiestructurado es el equilibrio entre la rigidez tabular y el caos de los formatos binarios. Estos datos utilizan etiquetas jerárquicas para organizar la información, siendo los archivos JSON y los modelos BIM IFC los ejemplos más potentes. Esta estructura permite que cada elemento constructivo contenga una riqueza de metadatos técnica que facilita la gestión del ciclo de vida de cualquier infraestructura.
Esta flexibilidad es la clave de la compatibilidad técnica en proyectos STEM de gran escala que involucran múltiples plataformas de software Un archivo IFC permite que los datos de materiales, proveedores y mantenimiento viajen integrados con la geometría sin corromper la base de datos general. Dominar este tipo de dataset asegura que la toma de decisiones técnica sea fluida y que la información sea recuperable décadas después de la construcción inicial.
Importancia de los datasets
La utilidad de un dataset curado se manifiesta de forma inmediata al eliminar las horas improductivas dedicadas a la búsqueda y validación de información dispersa. Disponer de datos limpios permite detectar cuellos de botella operativos en cuestión de minutos, transformando el flujo de trabajo de una actitud reactiva a una proactiva. Esta eficiencia libera carga de trabajo para tareas de mayor valor añadido, reduciendo errores de cálculo.
A largo plazo la acumulación estratégica de estos datos redefine por completo el rendimiento de las infraestructuras y la naturaleza misma de las profesiones técnicas. La transición hacia el mantenimiento predictivo permite que las estructuras «hablen», alertando sobre fatigas antes de que ocurra un fallo catastrófico. Este cambio desplaza el rol del ingeniero desde la supervisión manual hacia la orquestación de sistemas inteligentes, donde el éxito profesional dependerá de la capacidad para interpretar grandes colecciones de datos. Aquellas empresas que hoy inviertan en la calidad de su conjunto de datos alcanzarán niveles de rendimiento y escalabilidad inalcanzables para los modelos de gestión tradicionales.
¿Dónde localizar los datasets?
La diferencia entre un análisis de rigor y un simple ejercicio teórico reside en la fuente. El primer paso es mapear los catálogos de datos disponibles según su utilidad operativa y su procedencia:
- Kaggle (El campo de entrenamiento): Referente global para el entrenamiento y benchmarking de algoritmos. Es ideal para validar hipótesis frente a datos curados internacionalmente antes de aplicarlos a entornos reales.
- Google Dataset Search (El buscador universal): Indexa millones de colecciones de datos académicos y técnicos bajo un estándar de metadatos unificado, facilitando el acceso a estudios de universidades de prestigio.
- IEEE DataPort (El estándar de ingeniería): Repositorio de alta confianza que ofrece datasets validados académicamente para proyectos de ingeniería eléctrica, electrónica y civil.
- Portales de Datos Abiertos (La realidad del terreno): Recursos oficiales de valor incalculable para el análisis de contexto local y gestión de obra pública, destacando plataformas como:
- datos.gob.es (España): Registros masivos de cartografía, infraestructuras y servicios del IGN.
- datos.gov.co (Colombia): Datos esenciales para entender la realidad física y orográfica del país.
- datos.gob.mx (México): Fuente crítica para el análisis de infraestructura y desarrollo social.


