

.jpg)
Descubre cómo los avances en Inteligencia artificial pueden mejorar los diagnósticos médicos con redes neuronales convolucionales a través de este TFM.

¿Conoces la importancia de los avances en inteligencia artificial y su aplicación en el campo de la salud? ¿Sabías que los modelos de IA pueden desempeñar un papel crucial en la clasificación de imágenes médicas? El uso de redes neuronales convolucionales para la clasificación de imágenes de tumores cerebrales es un área de investigación revolucionaria que promete mejorar significativamente la precisión y la rapidez en los diagnósticos.
El Máster en Inteligencia Artificial: Gestión e Implantación de Modelos es uno de los másteres destacados de Structuralia, ya que proporciona los conocimientos y habilidades necesarias para el desarrollo y la implementación de modelos de IA avanzados. Este interesante y profundo TFM, titulado "Modelos de IA para la Clasificación de Imágenes de Tumores Cerebrales Haciendo Uso de Redes Neuronales Convolucionales", realizado por nuestro ex-alumno Jorge Mairena, es un gran reflejo de ello.
TFM: Modelos de IA para la Clasificación de Imágenes de Tumores Cerebrales Haciendo Uso de Redes Neuronales Convolucionales
Un tumor cerebral es una masa o un crecimiento de células anormales en el cerebro que pueden ser tanto benignos, que no contienen células cancerosas, como malignos. Algunos tumores son primarios, es decir, se originan en el momento en el que sus células tienen mutaciones en su ADN, por el contrario, existen tumores metastásicos que originariamente aparecieron en una parte del cuerpo y que por metástasis han llegado al cerebro. Existen muchos tipos de tumores cerebrales, pero en este estudio nos centraremos en 3 tipos: meningioma (surge de las meninges), glioma (se desarrolla en el cerebro y la médula espinal) y el tumor pituitario (se desarrollan en la glándula pituitaria).
No hay forma de prevenir el cáncer de cerebro, pero es primordial conseguir un correcto diagnóstico para su tratamiento. Actualmente, una de las maneras de los profesionales de la salud para reconocer el tipo de tumor es a través de imágenes por resonancia magnética (IRM). Se trata de una técnica no invasiva que permite la visualización de estructuras internas del cuerpo, pero en muchos casos, es necesaria otras prácticas como la biopsia para confirmar el tipo de tumor, debido a que gran parte de los datos disponibles a través de las imágenes de resonancia magnética no se pueden detectar a simple vista, como es el caso de los detalles relacionados con la forma, textura o la intensidad del tumor.
Objetivos de TFM
El objetivo de este trabajo es determinar el tipo de tumor cerebral presente en diferentes imágenes a través de un modelo de red neuronal convolucional en 4 clases, que incluyen los 3 tipos de tumores cerebrales meningioma, glioma o tumor pituitario más la clase de no tumor, en caso de no encontrar ninguno en la imagen.
Objetivos generales:
-
-
Determinar el tipo de tumor cerebral presente en diferentes imágenes a través de un modelo de red neuronal convolucional.
-
Desarrollar una interfaz web para implementar el modelo donde se visualicen los resultados de las predicciones.
-
Objetivos específicos:
-
-
Utilizar una Red Neuronal Convolucional para la predicción del tumor.
-
Conseguir una predicción del tipo de tumor con una precisión de mínimo 90%.
-
Contexto y Justificación del Trabajo
Hoy en día el estudio de aprendizaje profundo es primordial en el ámbito de salud ya que gracias a la creación de modelos de inteligencia artificial se puede ayudar al personal sanitario a detectar ciertas enfermedades con una gran precisión y poder aplicar el tratamiento correcto.
Caso de Uso
El problema del que se busca solución es la identificación y clasificación de tumores cerebrales. En este trabajo en concreto se ha construido un modelo de red neuronal convolucional con la capacidad de clasificar entre 3 tipos diferentes de tumores cerebrales: meningioma, gliomas y tumor pituitario.
Selección y Análisis del conjunto de datos
- Se utilizó un conjunto de datos de Kaggle que cuenta con 4 clases diferentes: meningiomas, gliomas, tumores pituitarios y no tumor. Este conjunto de datos cuenta con resonancias magnéticas en formato de imágenes digitales, clasificadas en las diferentes clases.
Fuente: Kaggle - Brain Tumor MRI Dataset
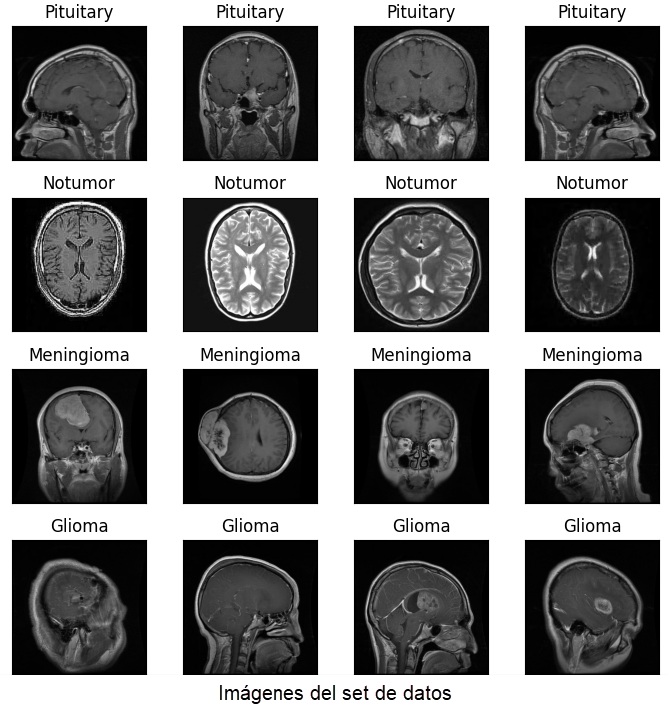
El estudio realizado contiene 7023 imágenes divididas en datos de entrenamiento y de pruebas.
|
Datos |
Glioma |
Meningioma |
No Tumor |
Pituitario |
Total |
|
Entrenamiento |
1321 |
1339 |
1595 |
1457 |
5712 |
|
Pruebas |
300 |
306 |
405 |
300 |
1311 |
|
Total |
1621 |
1645 |
2000 |
1757 |
7023 |
2. Se unificaron los datos de entrenamiento y pruebas quedando las clases distribuidas de la siguiente manera:
3. Creamos un DataFrame de los datos unificados y lo barajamos.
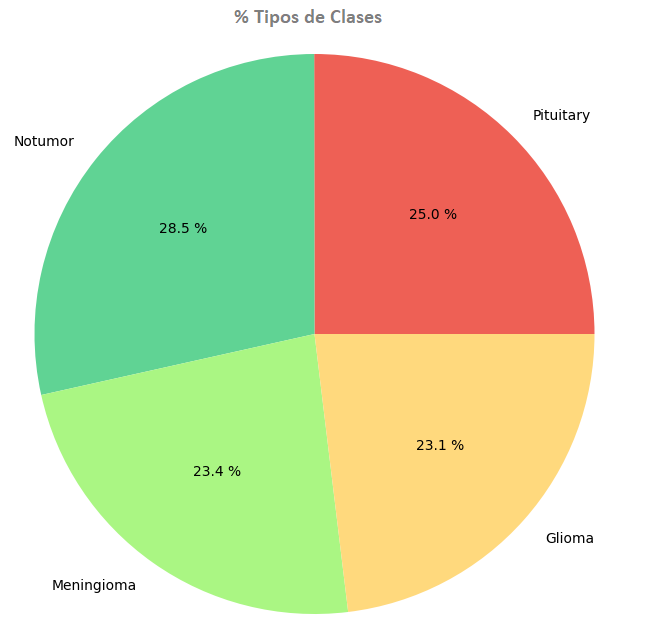
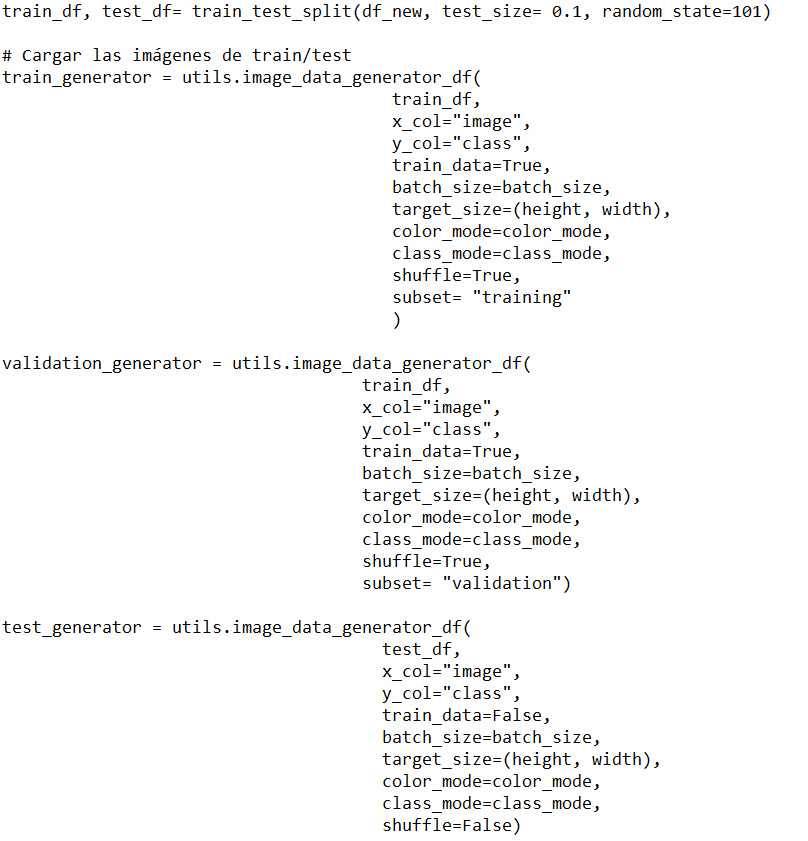
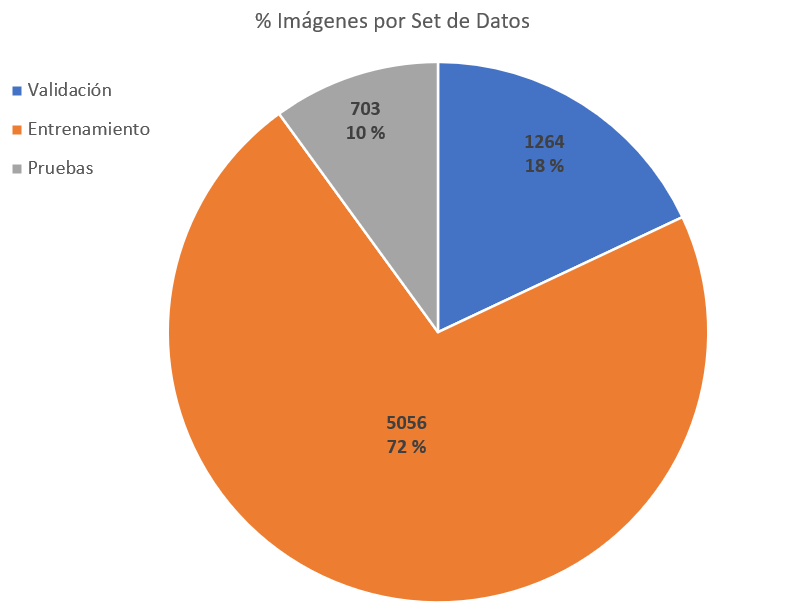
4. Dividimos el conjunto de datos barajados en tres porciones con una relación de 72: 18: 10 para entrenamiento, validación y pruebas respectivamente.
Utilizamos la técnica de Data Augmentation para aumentar artificialmente el conjunto de datos de entrenamiento ya que es pequeño, de esta forma ayudamos a mejorar la precisión de los modelos, mitigamos el overfitting y reducimos el costo operativo de etiquetar y limpiar el conjunto de datos sin procesar.

Desarrollando nuestros Modelos
Se desarrollaron tres modelos de redes neuronales, el primero fue una construcción manual utilizando un modelo personalizado de tipo Sequential para el segundo y tercer modelo se utilizó el aprendizaje por transferencia de las librerías de Keras InceptionResNetV2 e InceptionV3.
Parámetros de las clases:

Configuración de Modelos:
-
-
Modelo Personalizado:
-

-
-
Modelo InceptionResnetV2:
-

-
-
Modelo InceptionV3:
-


Entrenamos nuestros modelos y guardamos sus mejores configuraciones:
-
-
InceptionV3
-

-
-
InceptionResNetV2
-

-
-
Personalizado
-

Evaluando los resultados
Para evaluar los resultados de los modelos se definen los conceptos que se van a utilizar.
1. La precisión:
Es la ratio de las predicciones positivas hechas que son acertadas. Con esta métrica se tiene una relación con los falsos positivos, de manera que si es alta es porque hay pocos falsos positivos. Así, se mide si todas las predicciones que el sistema ha dicho que son de una clase son en verdad de ella.
2. Accuracy:
Representa el ratio de las observaciones predichas correctamente entre las
observaciones totales que se han hecho. En general es una medida buena de la calidad de los modelos (cuanta más mejor) pero hay que tener en cuenta otros factores que no están presentes en esta medida, como el hecho de que haya simetría o no en los datos del modelo.
3. Recall (sensibilidad):
Representa el ratio de las observaciones correctamente predichas de un grupo frente al número de las que se tendría que haber hecho; es decir, mide la capacidad de, de todas las predicciones de una clase que debería haber hecho, cuantas ha hecho verdaderamente. Con ello se tiene una métrica relacionada con los falsos negativos.
4. F1 score:
Es una métrica que tiene una media ponderada de la precisión y de recall, teniendo así presente de forma simultánea tanto los falsos positivos como los falsos negativos, y es por ello más explicativa que la accuracy, sobre todo para situaciones donde hay un desbalanceo de los datos.
5. La predicción de entrenamiento (Train accuracy):
Es la precisión del modelo construido con los datos de entrenamiento.
6. La precisión de prueba (Test accuracy):
Es la precisión del modelo para datos que no ha visto nunca.
Presentamos sus respectivas gráficas de evolución del Accuracy y pérdidas durante las épocas de entrenamiento para cada modelo:
-
-
InceptionV3
-
-
-
InceptionResNetV2
-

-
-
Personalizado
-
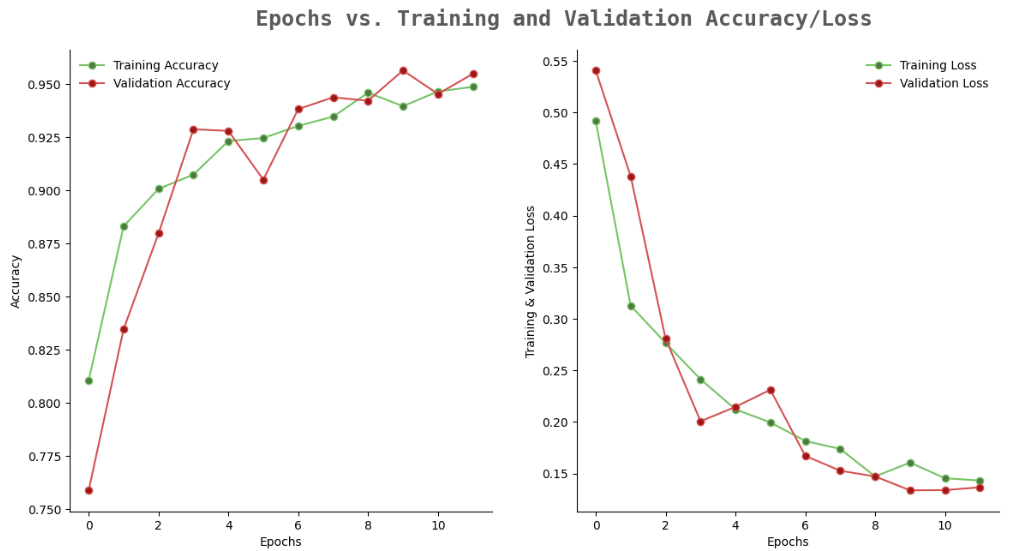
Vemos como en la red InceptionV3 no hay overfitting ni se aprecia un ruido marcado, el accuracy va aumentando por encima del 95 % y disminuyendo su función de pérdida.
En la red InceptionResNetV2 se aprecia que en las 2 primeras épocas hay ruido, pero luego se estabiliza y a partir de la época 4 va aprendiendo las características relevantes por tanto va aumentando su accuracy por encima del 95% e igual que disminuye su función de pérdida.
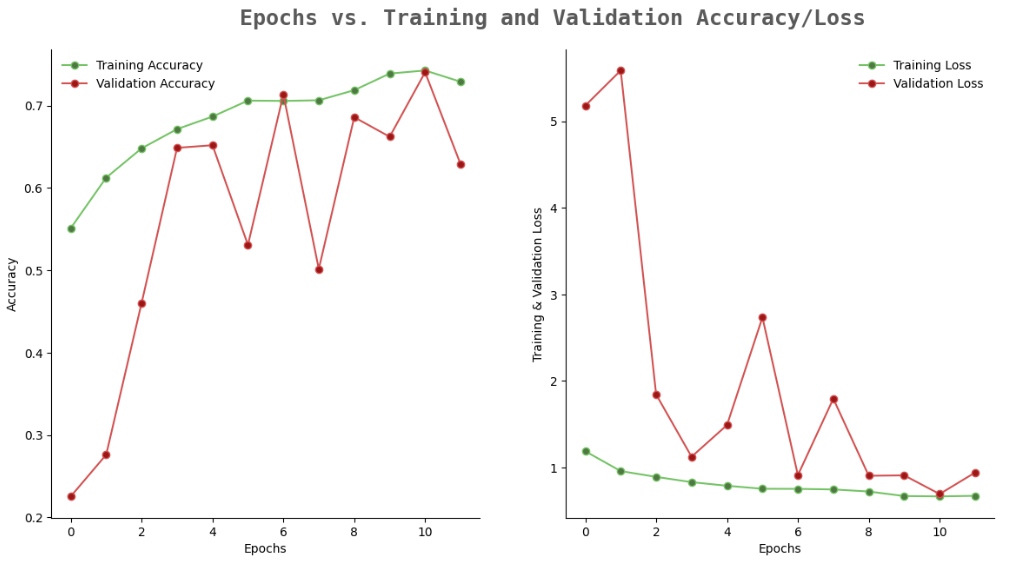
Para la red personalizada se aprecia claramente un Underfitting ya que no es capaz de captar los patrones relevantes del conjunto de datos de entrenamiento y validaciones resultando en un modelo deficiente que perjudicará las clasificaciones al menos para el conjunto de datos con el que se entrenó.
Calculamos el Accuracy de entrenamiento para cada modelo:

Testeamos los modelos con el conjunto de datos de pruebas y recolectamos sus estadísticas:

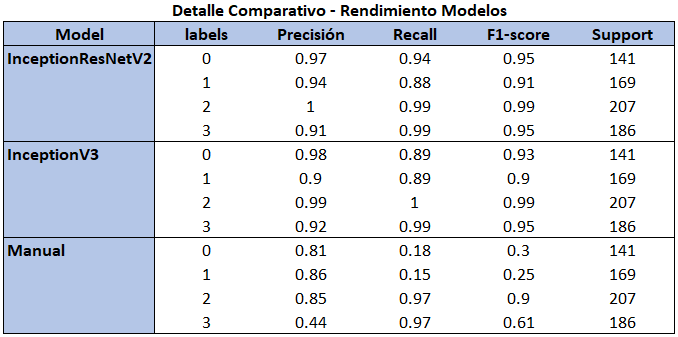
Se puso a prueba a los modelos con un conjunto de datos nunca vistos (test_generator) dando los mejores resultados InceptionRestNetV2 e InceptionV3 con un test accuracy del 95%.
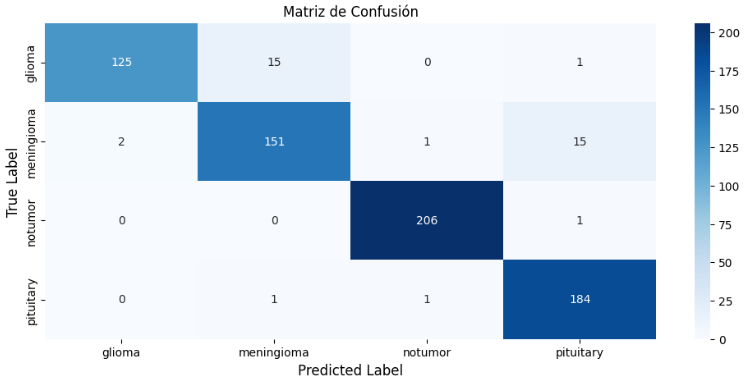
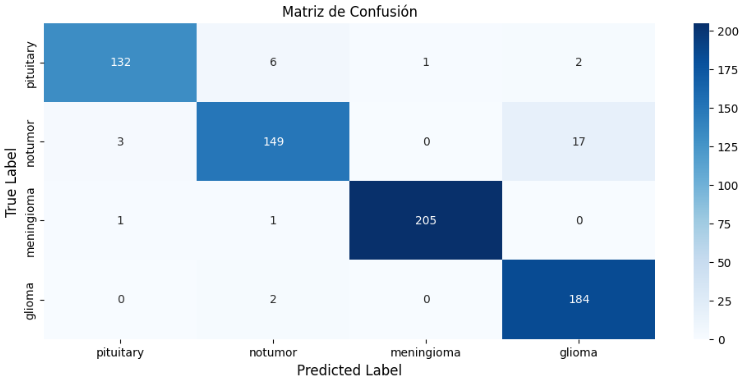
Como buena práctica generamos las matrices de confusión para saber que tan bien predijeron los modelos por cada categoría.

-
-
InceptionV3:
-
-
-
InceptionResNetV2
-
-
-
Personalizado:
-

Se puede apreciar como los modelos de aprendizaje por transferencia dieron mejores indicadores en sus resultados de predicción que el modelo personalizado esto es porque dichos modelos han aprendido a extraer características usando un gran conjunto de datos, lo que significa que podemos conseguir un modelo con gran capacidad de generalización incluso con un conjunto de datos pequeño como el nuestro.
Me llama la atención el modelo InceptionV3, aunque estuvo levemente por debajo en sus indicadores estadísticos que el modelo InceptionRestNetV2 (Ver imagen resumen comparativo) es un modelo mucho más ligero (Ver imagen Comparativa de parámetros) lo que reduce la cantidad de cálculos necesarios para procesar datos y esto se traduce a menos carga computacional e inferencias más rápidas.
La Importancia del conjunto de datos
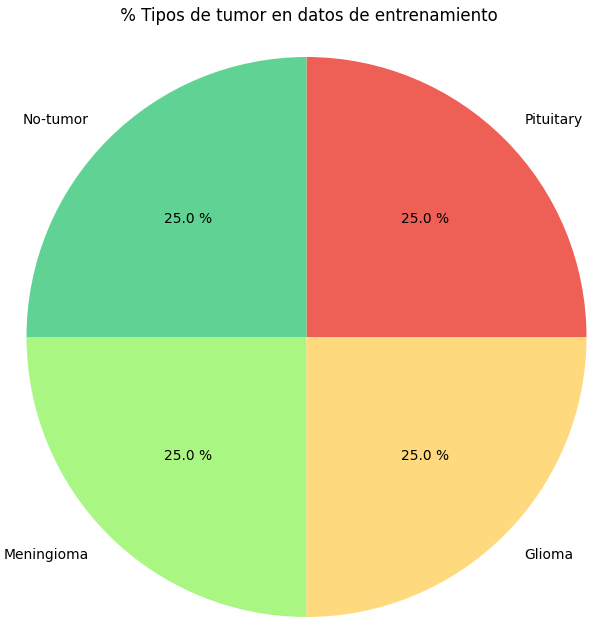
Para esta demostración se utiliza otro conjunto de datos de Kaggle mucho más grande que el anterior (7023 imágenes) para un total de 44,000 imágenes distribuidas equitativamente entre las clases glioma, meningioma, pituitario y no tumor.
Fuente: Tumores cerebrales - MRI - Dataset
Se reutiliza la configuración del modelo personalizado con los mismos parámetros de clases y métodos de optimización, entrenamos nuestro modelo y obtenemos las siguientes estadísticas:
-
Personalizado - Train Accuracy: 99.82 %
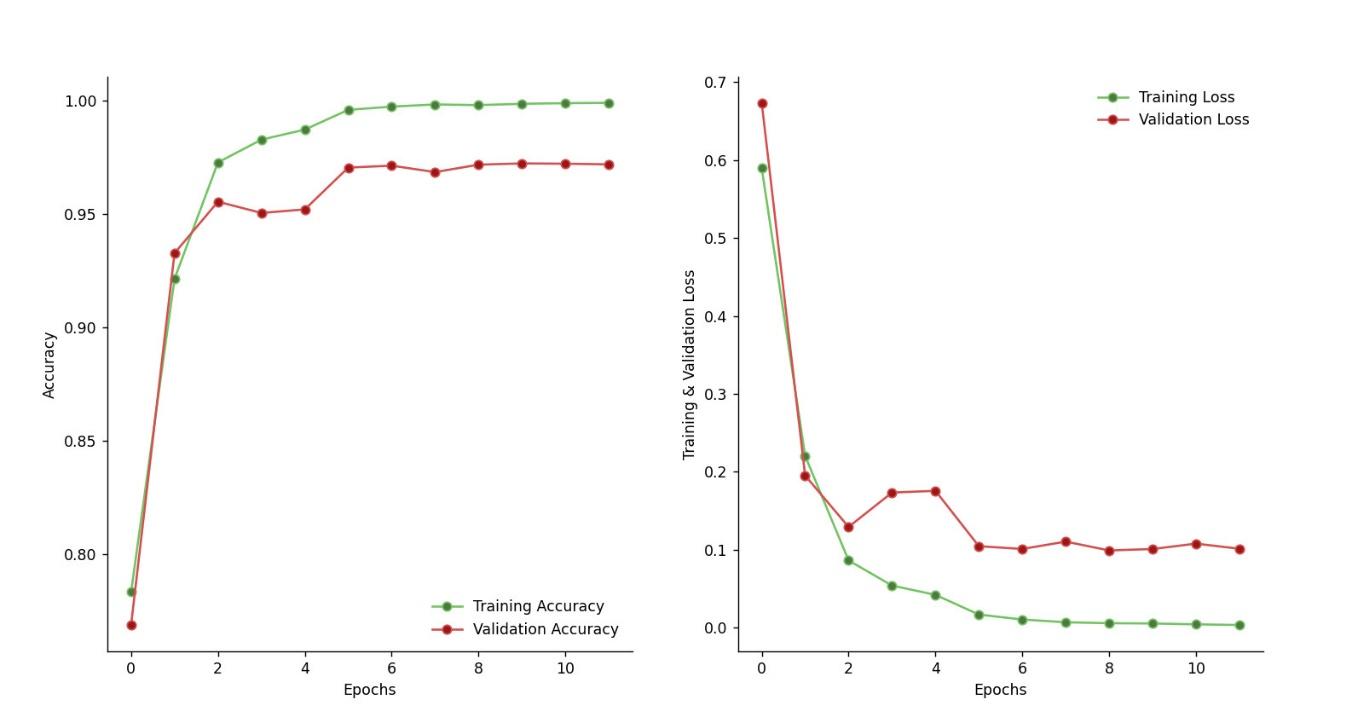
Se puede apreciar que este nuevo modelo converge rápidamente con un train accuracy de casi 100%, no se aprecia ruido ni overfitting generalizando muy bien y mejor que el resto de modelos por lo tanto proporcionará mejores predicciones.
Recolectamos las estadísticas para el conjunto de datos de pruebas (conjunto de datos nunca visto por el modelo).
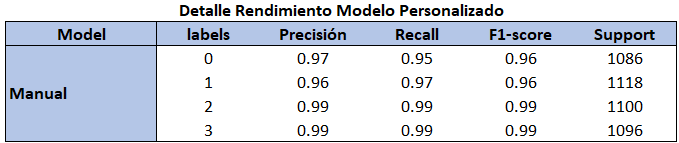

Prácticamente tenemos un modelo con una confianza en su predicción del 98% superior al resto de modelos.
Finalizamos mostrando su matriz de confusión.

Implementación
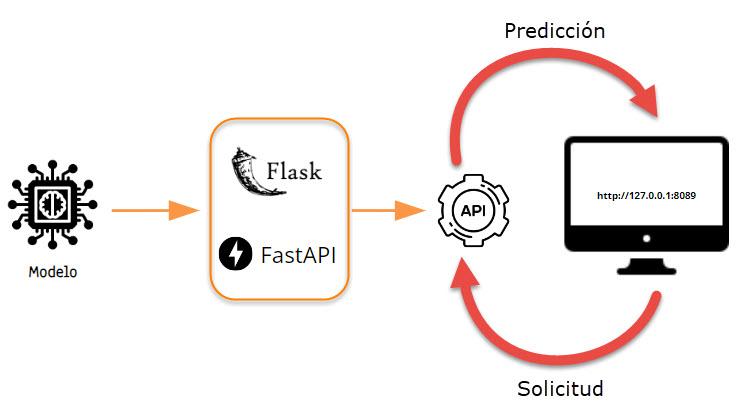
Fuente: ModelCheckpoint - Keras
Es importante brindarle al personal que va a hacer uso de nuestros modelos una aplicación que pueda ser accedida desde cualquier dispositivo y en cualquier momento. Para este fin proponemos un diseño de implementación básico para el despliegue de nuestros modelos a producción.
Se desarrolló una aplicación WEB que utiliza FLASK como Framework y un servicio REST API cuya función es la de servir las predicciones de nuestro modelo a las solicitudes de los usuarios. Para generar nuestro modelo se utilizó la librería de Keras.
Diseño de la interfaz principal

-
-
Interfaz web
-
.png?width=600&height=292&name=image%20(63).png)
Conclusiones
La IA está desempeñando un papel fundamental en la transformación del sector salud, ofreciendo mejoras significativas en el diagnóstico, tratamiento, gestión de datos y operaciones hospitalarias. Sin embargo, es crucial abordar los desafíos éticos como la privacidad de los datos, la transparencia de los algoritmos entre otros. Además, es esencial garantizar que los sistemas de IA se utilicen para complementar y no reemplazar el juicio clínico humano.
Este trabajo podría seguir especializándose implementando un localizador del tumor también en predecir su gravedad y por supuesto seguir aumentando la predicción hasta alcanzar el 99%. También es importante mencionar en aplicar mecanismos para
asegurar que la calidad de las predicciones no se vea afectadas a lo largo del
tiempo.
Reseña del Autor
.jpg?width=121&height=121&name=Fotos%20Contenidos%20(57).jpg) Jorge Isaak Mairena Alemán, Máster en Inteligencia Artificial: Gestión e Implantación de Modelos impartido por Structuralia y avalado por La Universidad Isabel I de España. Ingeniero de Sistemas de la Universidad Nacional de Ingeniería de Nicaragua (UNI). Postgrado en Inteligencia Artificial por la Universidad Nacional de Ingeniería, Especialista en Machine Learning y Desarrollo de Sistemas On Premise y Cloud en diversos ecosistemas tecnológicos avalado por empresas certificadoras internacionales como Oracle y Microsoft. Además de contar con la Certificación Internacional en Mejoras de Proceso Lean Agile Team Worker ISO 18404 avalado por la Empresa Esteos y Certificadora AENOR.
Jorge Isaak Mairena Alemán, Máster en Inteligencia Artificial: Gestión e Implantación de Modelos impartido por Structuralia y avalado por La Universidad Isabel I de España. Ingeniero de Sistemas de la Universidad Nacional de Ingeniería de Nicaragua (UNI). Postgrado en Inteligencia Artificial por la Universidad Nacional de Ingeniería, Especialista en Machine Learning y Desarrollo de Sistemas On Premise y Cloud en diversos ecosistemas tecnológicos avalado por empresas certificadoras internacionales como Oracle y Microsoft. Además de contar con la Certificación Internacional en Mejoras de Proceso Lean Agile Team Worker ISO 18404 avalado por la Empresa Esteos y Certificadora AENOR.
Con más de 14 años de experiencia en el Sector Salud | Comercial | Informática. Actualmente se desempeña como Consultor Especialista de Sistemas Informáticos en el Ministerio de Salud de Nicaragua donde realiza la Supervisión del desarrollo, seguimiento e Implementación de Sistemas Hospitalarios.
Ha participado en el WorkShops ESAVI FHIR Connectathon 2023 Latinoamérica como parte del equipo del Ministerio de Salud representando a Nicaragua en la implementación de estándares y soluciones de interoperabilidad en salud HL7 - FHIR con excelentes resultados quedando entre los 3 primeros lugares entre más de 23 países convocados.
Team Leader de equipos desarrolladores del expediente digital en Nicaragua proyecto articulado por el Ministerio de Salud del cual recibió premio en el año 2023 de la OMS – OPS por innovación en salud digital siendo el país líder en la región Centroamericana en la implementación del expediente electrónico del paciente.
Testimonio del autor:
1. ¿Qué es lo que más destacarías del máster?
"Indiscutiblemente puedo destacar la experiencia y dominio del tema de los docentes y se vio reflejado en el seguimiento oportuno a las dudas de los compañeros a través de la comunidad. Otro punto importante es la documentación proporcionada en diferentes formatos (videos, pdf y enlaces externos a fuentes seguras para las herramientas a utilizar). Todo esto fue posible gracias a una plataforma amigable e intuitiva."
2. ¿En qué te ha ayudado o crees que te podría ayudar en tu actual o futuro desarrollo profesional?
"Considero que me ha ayudado a ampliar el abanico de oportunidades en donde se puede aplicar la Inteligencia Artificial y el Machine Learning en las diferentes industrias, así como las técnicas mas refinadas de algoritmos a utilizar según el caso. Todo esto a despertado aún más en mí la necesidad de seguir profundizando en el tema y desarrollar sistemas inteligentes para el beneficio de la sociedad tomando como base la continuidad en la implementación de mi proyecto final."
3. ¿Por qué elegiste Structuralia?
"Después de analizar varias ofertas de maestrías online me decidí por Structuralia ya que su contenido era justo lo que andaba buscando para profundizar mis conocimientos además que el Máster contaba con la doble titulación avalado por una Universidad Europea y si a eso le sumamos la opción a beca pues superaba por mucho al resto de ofertas."




