

.jpg)
Descubre cómo el Trabajo de Fin de Máster en Big Data explora la predicción de movimientos bursátiles con inteligencia artificial, ofreciendo perspectivas innovadoras.

Proyecto TFM: Predicción de series temporales con modelos de IA
Este artículo se centra en el Trabajo de Fin de Máster en Big Data y Business Analytics de nuestro ex alumno del Daniel Cano Alvira, que busca explorar el potencial de la inteligencia artificial para predecir movimientos en los índices bursátiles con el objetivo de lograr un rendimiento positivo en los mercados financieros. El proyecto representa posibles aplicaciones de técnicas de inteligencia artificial en el campo de las inversiones, ofreciendo y desarrollando dos posibles perspectivas para afrontar el reto.
Objetivos del TFM
El objetivo del trabajo es la creación de un modelo de predicción de precios para aplicar a los mercados financieros. Para ello se usará Python con el fin de descargar los precios de diversos activos financieros conectándose a Yahoo Finance. No se incluirá el código desarrollado en este post para que no se prolongue demasiado.
Datos del Proyecto
Yahoo Finance es un servicio en línea proporcionado por Yahoo que ofrece una variedad de información financiera de forma gratuita, incluyendo datos sobre acciones, noticias financieras, herramientas de análisis y recursos para el seguimiento de mercados e inversiones.
Si bien no goza de una API oficial, gracias a la gran cantidad de repositorios disponibles en GitHub se podrán obtener los datos de cotizaciones de forma sencilla. El repositorio que se va a emplear se llama yfinance, desarrollado por Ran Aroussi, es la mejor alternativa para Yahoo Finance, si bien cada vez consta de más métodos obsoletos debido a la mejora de la seguridad de la página web contra el webscraping. Para el alcance de este proyecto solo se usará el método “Ticker” y se descargarán los datos de cotización de algunos índices bursátiles de la página de índices mundiales de Yahoo Finance mediante un webscraping muy sencillo. Un índice bursátil es un dato calculado mediante una ecuación sobre unos activos concretos con el objetivo de reflejar las variaciones de valor o rentabilidades de los activos que lo componen. Los datos se devolverán como velas japonesas, este tipo de dato consta de 4 componentes principales para describir el movimiento del precio del activo subyacente. Dichos componentes se explican a continuación junto con el resto de datos disponibles en la tabla obtenida.
-
Date: Fecha y hora de inicio de la vela japonesa. Al descargar velas de intervalo diario existirá una por día y por lo tanto la fecha será diaria.
-
Open (Apertura): Precio del activo al inicio del intervalo temporal de la vela.
-
High (Máximo): Precio máximo de cotización durante el intervalo temporal de la vela.
-
Low (Mínimo): Precio mínimo de cotización durante el intervalo temporal de la vela.
-
Close (Cierre): Precio del activo al final del intervalo temporal de la vela.
-
Volume (Volumen): Cantidad de contratos que se han transferido en el total de transacciones llevadas a cabo en el intervalo temporal de la vela.
-
Dividends (Dividendos): Cantidad monetaria retribuida por acción a los dueños de acciones de una empresa. Esto solo aplica cuando se trata de acciones o ETFs.
-
Stock Splits (División de acciones): Relación se multiplica el número de acciones para tener más disponibles en el mercado o menos. Si es menor a uno se considera una división inversa, en la que se reduce el número de acciones, normalmente con el objetivo de subir el precio. Si es mayor que uno la cantidad de acciones aumenta, bajando el precio y haciéndolas más accesibles. Esto solo aplica cuando se trata de acciones o ETFs.
Para nuestro caso además se calcularán nuevos datos a partir de los ya mencionados con el objetivo de obtener mayor capacidad de predicción. A continuación, se explican los principales.
-
Range: Rango de precios de cotización de esa vela, se obtiene restando el máximo menos el mínimo.
-
Range per unit: Rango en por unidad, se calcula dividiendo el rango (Range) entre el precio de apertura (Open).
-
Open to Close: Rango entre apertura y cierre, se obtiene restando el precio de cierre (Close) menos el precio de apertura (Open). Cabe destacar que al contrario que el Rango este dato será negativo cuando la cotización descienda.
-
Open to Close per unit: Rango entre apertura y cierre dividido entre el precio de apertura (Open).
-
Gap: Diferencia entre el precio de apertura actual y el precio de cierre de la vela anterior.
-
Gap per unit: Diferencia entre el precio de apertura actual y el precio de cierre de la vela anterior dividida entre el cierre anterior.
-
Moving Average difference per unit: Diferencia entre el precio de apertura actual y las medias móviles de 10, 20, 50, 100 y 200 periodos entre la media.
-
Week Day: Número del día de la semana, entre el 0 y el 4 al que pertenece la vela.
Selección del universo de activos a estudiar
Una vez realizado el webscraping de los índices bursátiles se decidió filtrarlos debido a la cantidad inicial. Mediante el análisis de las series temporales de los distintos índices se concluyó que los más operados son los del mercado americano y que hay índices que tienen un rango diario considerablemente inferior a los demás, como son: N225, IXIC, GSPC o AORD. Cabe destacar que el SPY consta de un volumen decente, suficiente volatilidad y un precio correcto para permitir eficiencia en la gestión de riesgo con la operativa real. A continuación, veremos la correlación entre los activos seleccionados.
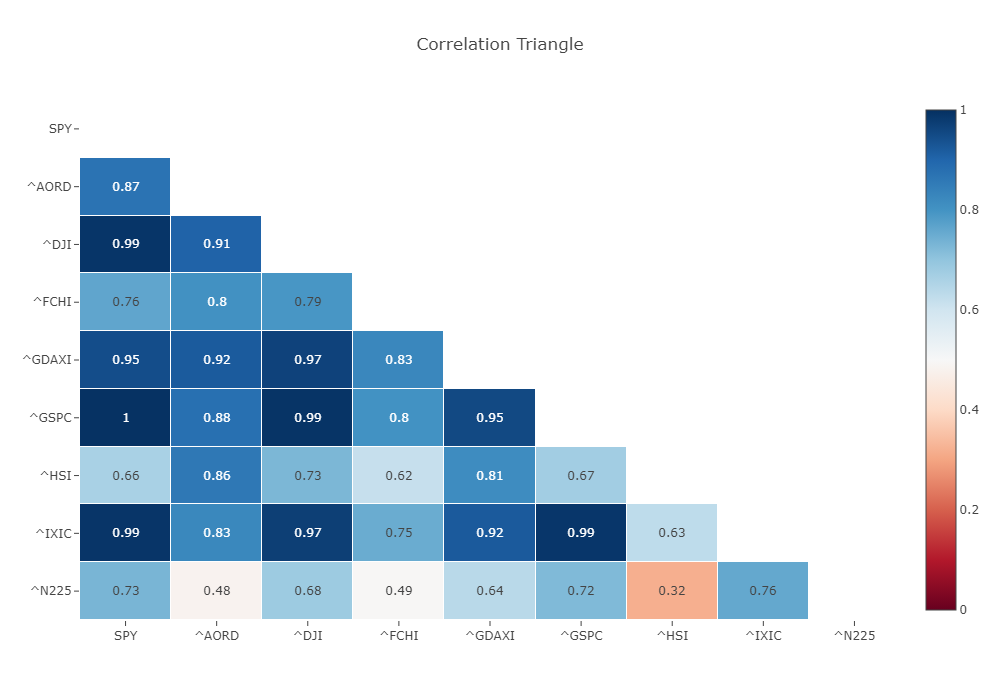
A partir de la figura se puede observar la alta correlación entre los mismos, no siendo negativa en ningún caso e inferior a 0.5 solo en 3 casos. Dado que los índices proporcionan una visión general de la dirección y la salud de un segmento particular del mercado financiero, cuando dicho índice representa las mejores empresas de un país se suele considerar que su rendimiento será parecido a la salud económica del país. Si se une esto a la alta correlación entre los índices de distintos países se podría considerar que los ciclos económicos se encuentran relativamente sincronizados, probablemente debido a la gran globalización y dependencia internacional. Podemos deducir de todo ello que probablemente los propios índices tengan cierto valor predictivo entre ellos, esta será la hipótesis del segundo caso de estudio que se realizará.
Métricas de valoración de estrategias
Para validar los sistemas de predicción se calcularán las métricas estándar del sector y algunas que personalmente creo pueden ser interesantes y ayudan a la compresión del comportamiento del sistema. Todas estas métricas están basadas en las operaciones pasadas y por lo tanto son puramente orientativas y cambiantes con el tiempo.
1. Rentabilidad
Mide el rendimiento en términos de ganancia neta en relación con el capital invertido. Una rentabilidad positiva indica que el sistema está generando beneficios.
Rentabilidad=Ganancia NetaCapital Invertido×100
2. Ratio de Sharpe
Evalúa la relación entre el rendimiento adicional obtenido por asumir riesgos y la volatilidad del sistema. Un ratio de Sharpe alto indica un mejor rendimiento ajustado al riesgo. En la práctica, el rendimiento de los bonos del gobierno a corto plazo, como los bonos del Tesoro de Estados Unidos con vencimientos de tres o seis meses, es comúnmente utilizado como una aproximación de la tasa libre de riesgo. Esta elección se basa en la suposición de que estos bonos son relativamente seguros y líquidos. Ya que esto queda fuera del ámbito de estudio de este trabajo se va a usar una tasa libre de riesgo igual a 0 que sería el equivalente a tener el dinero en la cuenta del banco.
Ratio Sharpe=Rendimiento Esperado - Tasa Libre de RiesgoVolatilidad×100
3. Ratio de Sortino
Se trata de una métrica muy similar al ratio de Sharpe pero en la cual en vez de emplear la volatilidad total del sistema solo se tendrá en cuenta la de las posiciones negativas.
Ratio de Sortino=Rendimiento Esperado - Tasa Libre de RiesgoDesviación Estándar Negativa×100
4. Máxima pérdida
Mide la mayor disminución del balance de la cartera desde el máximo. Cuanto menor sea mayor será la estabilidad del sistema.
Máxima Pérdida=1-Balance ActualBalance Máximo×100
5. Porcentaje de operaciones ganadoras
Probabilidad de que una operación cualquiera sea ganadora.
Probabilidad de Ganar=Número de Operaciones ExitosasNúmero Total de Operaciones×100
6. Ratio de beneficio entre riesgo
Evalúa la relación entre las ganancias y las pérdidas, ayudando a determinar si el sistema está generando recompensas proporcionalmente mayores a los riesgos asumidos.
Ratio Beneficio-Riesgo=Beneficio Promedio por OperaciónPérdida Promedio por Operación
7. Esperanza matemática
Representa el promedio ponderado de todos los posibles resultados de una variable aleatoria, tomando en cuenta la probabilidad de que cada resultado ocurra. En el contexto financiero, la esperanza matemática puede utilizarse para calcular el rendimiento esperado de una inversión, ayudando a los inversores a tomar decisiones informadas sobre dónde asignar sus recursos.
Esperanza=(Probabilidad de Ganar * Beneficio Promedio por Operación -
Probabilidad de Perder * Pérdida Promedio por Operación)×100
Siendo: Probabilidad de Perder = 1-Probabilidad de Ganar
De la ecuación previa se puede entender la relación entre la probabilidad de ganar y el ratio de riesgo. Habrá un punto límite tras el cual la esperanza sea negativa para cada valor de probabilidad de ganancia puesto que cuanto menor sea mayor tendrá que ser el retorno de la inversión en relación a la pérdida (ratio de riesgo) para seguir siendo rentable.
8. Tamaño de Kelly
Fórmula utilizada en la teoría de la gestión de capital y en la teoría de la información para determinar el tamaño óptimo de una serie de apuestas. Es aplicable en situaciones donde se realizan apuestas o inversiones sucesivas, busca maximizar el crecimiento del capital a largo plazo. Es importante destacar que el Criterio de Kelly es una estrategia agresiva y, si bien puede maximizar el crecimiento a largo plazo, también puede llevar a la pérdida de una gran parte del capital en el corto plazo si las estimaciones de las probabilidades son inexactas.
Kelly=Probabilidad de Ganar -Probabilidad de PerderRatio Beneficio-Riesgo×100
9. Porcentaje de tiempo en el mercado
Relación entre la cantidad de días que se tienen operaciones en mercado y la cantidad de días que se ha aplicado el sistema. Se suele considerar mejor cuando el porcentaje es menor ya que se está expuesto a menos riesgos y menos comisiones, en caso de que haya comisiones de mantenimiento.
Tasa de Exposición=Tiempo con Posiciones AbiertasTiempo de Ejecución del Sistema×100
Primer caso de estudio
El primer intento de predicción consistirá en la aplicación de un modelo en inteligencia artificial basado únicamente en las características derivadas del precio del propio activo. Se hará una comparativa sobre la aplicación de los modelos:
-
Regresión Lineal
-
Regresión Logística
-
K Vecinos Cercanos (K Nearest Neighbours or KNN)
-
Ingenuo Bayes (Naive Bayes)
-
Red Neuronal (Neural Network)
-
Bosque Aleatorio (Random Forest)
-
Máquina de Vector de Soporte (Support Vector Machine o SVM)
Si bien se ha desarrollado el código de dichos modelos en vez de usar las librerías más comunes no se publicará para no extender el post demasiado. Si se quiere acceso consultar al autor.
Para no extender la duración del proyecto se realizó una pequeña optimización antes de comparar los modelos, a continuación se mostrarán 3 gráficas distintas que se usarán para comparar los resultados con datos de entrenamiento y los de prueba con el objetivo final de identificar posibles sobreoptimizaciones.
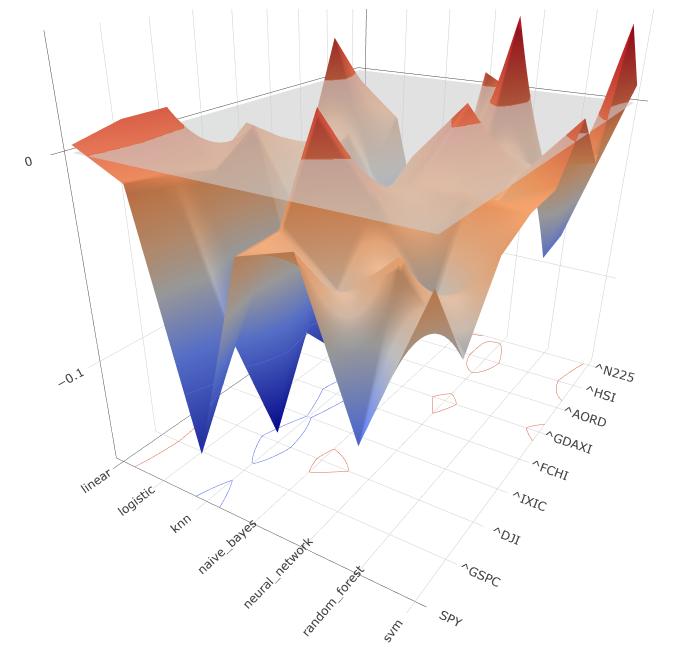
La primera gráfica muestra la variación de la probabilidad de ganar entre el resultado de la predicción con datos de prueba y los datos de entrenamiento. Se puede deducir que cuanto más cercano a 0 sea el valor menor será el sobre ajuste. En las líneas de nivel proyectadas en el plano inferior se puede apreciar que el modelo KNN es el más sobre ajustado de todos mientras que los modelos de Regresión Lineal y Red Neuronal son los menos sobre ajustados, llegando a desenvolverse mejor con los datos de prueba que con los de entrenamiento en algunos activos.
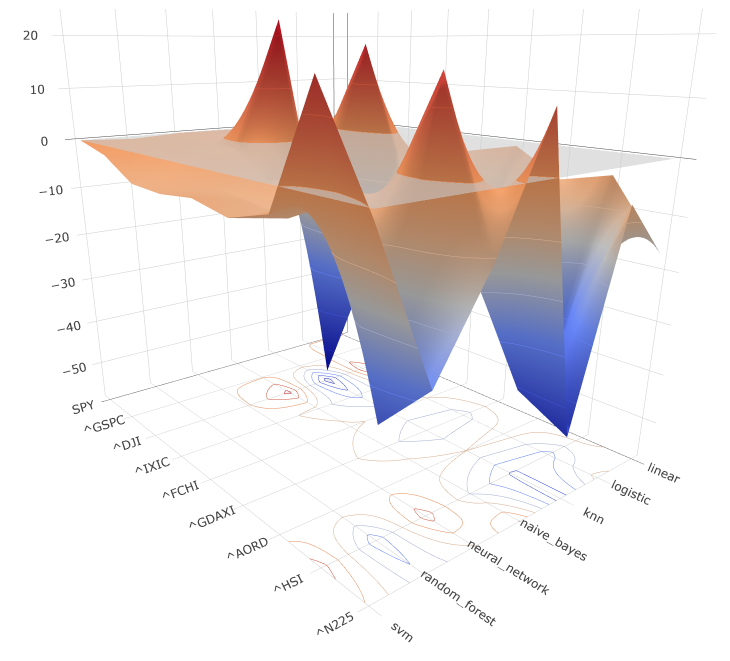
En la siguiente figura se puede observar la diferencia en la esperanza matemática obtenida con los datos de entrenamiento y los datos de prueba. Dado que la probabilidad de ganar afecta a esperanza matemática se puede apreciar que los modelos en los que menos varía dicha métrica entre el entrenamiento y los datos de prueba son los mismos que en la gráfica previa. Si bien el modelo de Regresión Lineal es el que menos varía, al tener en cuenta todos los activos el modelo KNN vuelve a ser el más sobre ajustado, reafirmando así lo deducido previamente.
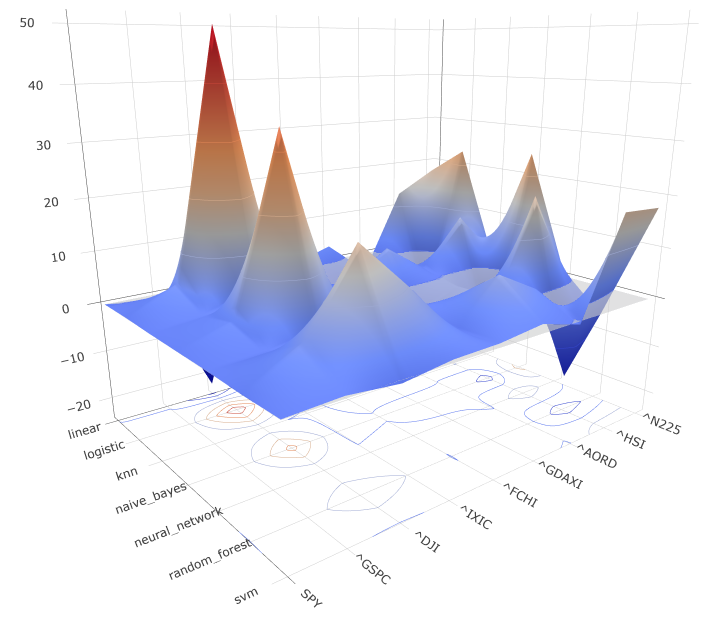
Los modelos Naive Bayes y KNN son los que menor esperanza matemática media obtienen, como se puede ver en la siguiente gráfica. Cabe resaltar que los modelos de Regresión Lineal, Redes Neuronales y SVM son los que tienen menos activos con esperanza matemática negativa, haciendo que sean los más polivalentes. No se han añadido los resultados aplicando el modelo PCA sobre las características usadas puesto que los resultados han sido peores de los obtenidos sin su aplicación.
Por último se calculará la evolución del balance de cada modelo para cada activo estudiado.
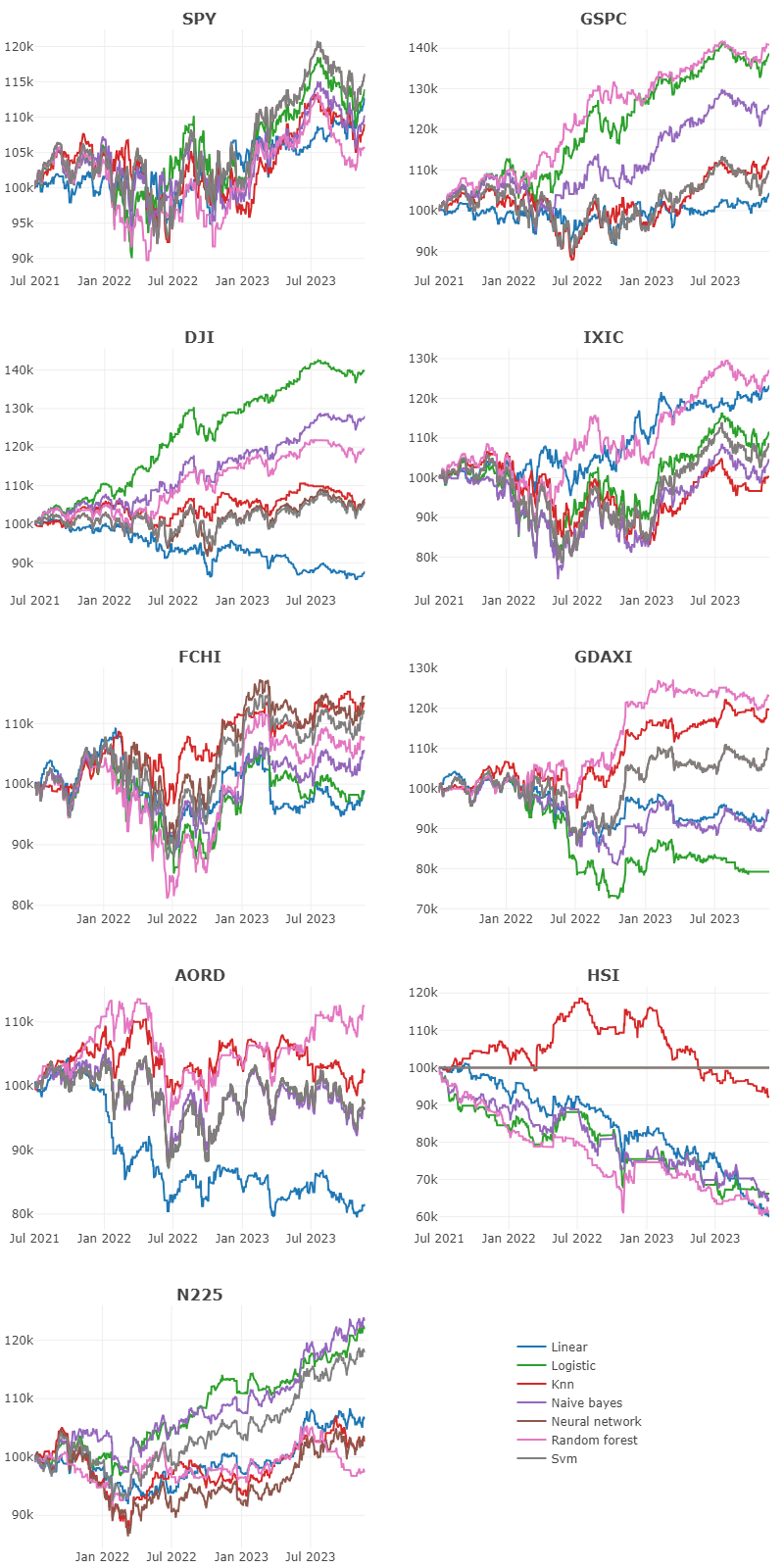
Se considerará un capital inicial de 100.000,0$ y una asignación del 100 % a cada uno de los modelos. Dado que la gestión del riesgo queda fuera del alcance de este trabajo se operará con el capital total cada vez que se realice una operación. Además, se considerarán solo las operaciones en largo y unas comisiones nulas. En la figura se puede observar un gráfico para cada activo con la correspondiente curva de balance para cada modelo entrenado. Se puede apreciar que de forma general ningún modelo destaca, pero que hay modelos que operan relativamente bien los índices americanos y podría merecer la pena profundizar en ellas e introducir estrategias de gestión de riesgo.
Cabe destacar que solo se han usado dos años de datos para el estudio, que dichos años coinciden con un año de recesión y otro de inicio de expansión debido a las políticas llevadas a cabo por los bancos centrales. Sería conveniente llevar a cabo un estudio sobre mayor cantidad de datos e incluir un test de walk forward.
Segundo caso de estudio
El segundo ejercicio consistirá en la predicción de los precios del SPY, un ETF que replica el comportamiento del SP500. La idea detrás de este ejercicio se basa en la diferencia horaria entre los diferentes mercados alrededor del mundo. Dado que el mercado asiático ha cerrado cuando el mercado americano abre sería coherente pensar que la sesión de ese día podría verse afectada por el comportamiento de los mercados que operan en husos horarios anteriores. Se dividirán los datos en partes iguales, siendo la primera mitad los datos de entrenamiento y la segunda mitad los datos a predecir. Además, se mantendrá la misma gestión operativa que en el ejercicio anterior.
En este caso los modelos estudiados serán los siguientes:
-
Regresión Lineal
-
Regresión Logística
-
K Vecinos Cercanos (K Nearest Neighbours or KNN)
-
Bosque Aleatorio (Random Forest)
La a continuación presenta un análisis comparativo de los modelos en términos de las métricas previamente definidas. Se puede observar que diferentes modelos destacan en diferentes métricas, resaltando la importancia de considerar múltiples criterios al evaluar estrategias financieras.
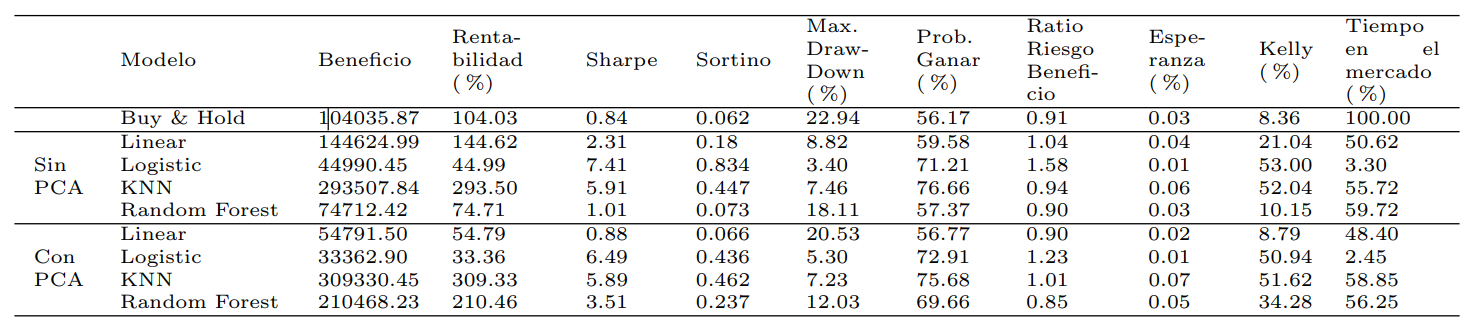
Se ha decidido tomar como referencia la estrategia de mantener el capital total invertido en el activo, comúnmente llamado “Buy & Hold”. Para esta estrategia se obtiene un beneficio de 104,035.87$ con una rentabilidad del 104.03 %. El Sharpe es 0.84, y el Sortino es 0.062. Además la máxima pérdida (Max. DrawDown) durante el periodo de prueba sería del 22.94 % y la probabilidad de ganar del 56.17 %. De forma general la aplicación del PCA no parece aportar valor, siendo la única excepción el modelo Random Forest. Aunque los beneficios pueden ser más bajos con el uso del PCA, la reducción en la dimensionalidad puede ser útil en términos de simplicidad y eficiencia computacional. El modelo de Regresión Logística es el que menor rentabilidad obtiene, esto se debe a la poca frecuencia operativa, siendo el tiempo de mercado cercano al 3 %. Esto y la alta fiabilidad lo convierten en el modelo con menor pérdida máxima y mayor ratio de Sharpe.
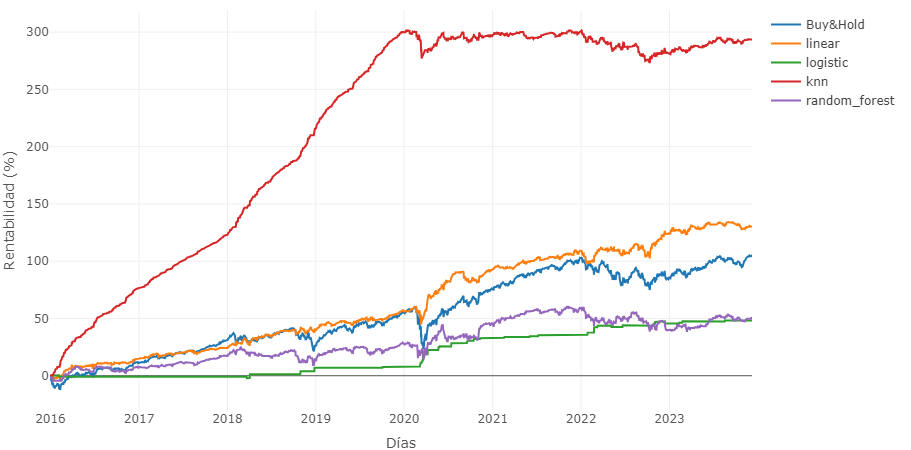
Por el otro lado el modelo de K Vecinos más Cercanos (KNN) es el que logra mayor rentabilidad, si bien esto se debe al sobre ajuste. Esto se da cuando el modelo se ajusta demasiado a los datos de entrenamiento, generando patrones poco generalizados. Se puede observar en la figura superior. Durante la primera mitad (entrenamiento) el capital aumenta de forma constante sin casi oscilación mientras que en los datos de prueba el capital oscila entre un máximo y un mínimo de forma constante.
La mejor estrategia de cara a su operación real sería la del modelo de Regresión Lineal, a la cual se le podrían incluir las señales producidas por el modelo de Regresión Logística con el objetivo de lograr así mayores beneficios. En este caso concreto las señales del modelo de Regresión Logístico se dan también por el modelo de Regresión Lineal por lo que no aportaría nada a menos que se tuviese en cuenta en la estrategia de gestión de riesgo.
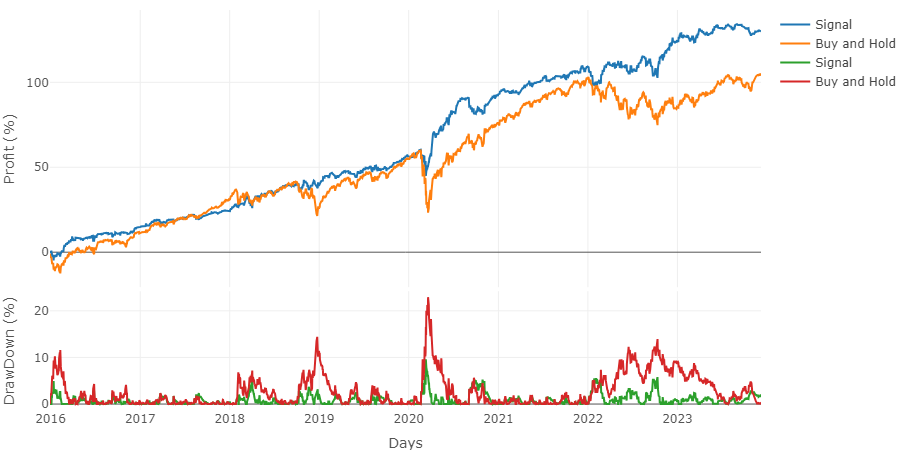
En la figura anterior se puede comparar el retorno y la pérdida acumulada en cada instante de la estrategia final y la estrategia con “Buy & Hold”. Como se puede apreciar la máxima pérdida es casi un tercio de la de “Buy & Hold” mientras que la rentabilidad final de la estrategia es 1.4 veces la de “Buy & Hold”. Todo ello permitiéndonos entrar a mercado solo la mitad de las veces.
Conclusiones
El objetivo del presente proyecto era estudiar la viabilidad de modelos de inteligencia artificial en la predicción de precios de activos operados en los mercado financieros. Se trata de un proyecto que se ha centrado más en los modelos y su comparación que en la gestión del capital y el porfolio. Si bien se ha demostrado que por muy de moda que esté la inteligencia artificial no es el santo grial, se ha conseguido obtener estrategias que pueden merecer la pena. En el primer ejercicio se ha visto que los modelos a menudo fracasarán en su tarea si se les alimenta solo con datos derivados de lo que se quiere predecir. Solo en los mercados más líquidos lograban una cierta precisión. El último ejercicio ha demostrado la necesidad de evitar sobre ajustar los modelos ya que pueden provocar un desastre cuando se apliquen a una operativa real. Además, se ha dejado en evidencia la importancia de la ingeniería de factores para obtener variables con mayor capacidad predictiva. La inteligencia artificial convive con nosotros en el día a día y lleva décadas siendo aplicada en los mercados financieros. Hará falta mucho estudio y recursos para poder obtener un sistema que pueda hacer frente a los retornos de los referentes del sector como Medallion Fund.
En el futuro sería conveniente incluir gestión operativa y de capital puesto que hay muchas variables que dependen de ello y se han supuesto en este trabajo. Algunas ideas por las que empezar podrían ser: añadir límite de pérdidas y de ganancias a las posiciones en vez de mantenerlas abiertas durante todo el día y definir un algoritmo para asignar el porcentaje de la cuenta a arriesgar en cada momento. Por otro lado, sería conveniente definir el tiempo a esperar para volver a entrenar al modelo, dado que para mantener al modelo actualizado es conveniente entrenarlo con datos nuevos. Habría que definir cada cuánto se debe entrenar y la cantidad de datos a utilizar, puesto que puede que patrones pasados contradigan a patrones actuales y deterioren la capacidad predictiva del modelo.
Reseña del autor
.jpg?width=167&height=167&name=Fotos%20Contenidos%20(46).jpg)
Daniel Cano, es Graduado en Ingeniería de la Energía por la Universidad Politécnica de Madrid y recientemente a cursado el Máster en Big Data y Business Analytics. Actualmente desarrolla sus labores profesionales en Técnicas Reunidas S.A., concretamente en el departamento de Transformación Digital. Daniel tiene tu propia página personal de proyectos, "One Made".
Testimonio del autor
1. ¿Por qué elegiste Structuralia?
"Mi empresa me dio la opción de poder formarme y especializarme con un máster, al tener que elegir entre varias opciones el Máster de Structuralia fue el que más me atrajo de todos."
2. ¿Qué es lo que más destacarías del máster?
"Lo que más destacaría es que entrega muy buena documentación y material en el Máster en Big Data y Business Analytics."
3. ¿En qué te ha ayudado o crees que te podría ayudar en tu actual o futuro desarrollo profesional?
"La realización del este Máster me ha ayudado a entender mejor y reforzar conceptos que ya sabía. También he podido aprender sobre nuevas herramientas de Big Data."




